Summer 2024
People’s Data
Project Leads: Giovanna Ceserani & Nicole Coleman
Whereas data used to be understood as structured, quantitative and categorical, developments in machine learning have made it possible to consider documents and collections of documents as data, providing context for the inferences drawn from those sources. But even with document or collection-level context, a fundamental principle behind critical data practices is still relevant: decisions about what becomes data and what does not empower some and disempower others. We add to this principle that making connections across datasets adds essential context for interpretation of data. Policy manuals from California law enforcement agencies are the basis of this case study, as they provide an ideal ground for using the affordances of AI to help us rethink the design of information retrieval systems. State legislation requires the policy manuals to be shared publicly to encourage “meaningful public input” on policy. And yet, the documents themselves are written to reduce the legal liability of law enforcement rather than enhance public understanding of law enforcement policies.
Project Members
Project Team
Nicole Coleman
Digital Research Architect, Stanford University Libraries
Giovanna Ceserani
Professor of Classics, and CESTA Faculty Director
Jiaju Liu
Undergraduate Researcher - Summer, 2024
Designing Pluralistic Data Structures for Mapping Military Equipment in Policing
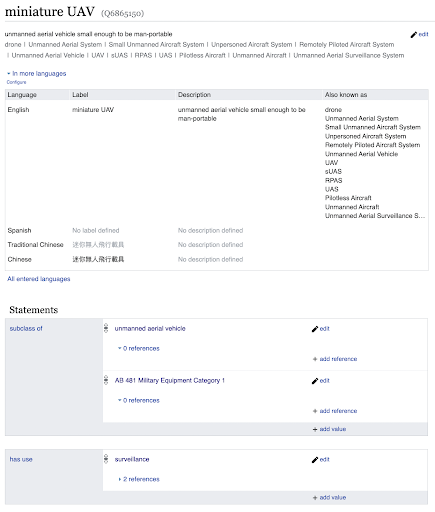
Over the summer, I worked with Jorge Gonzalez–another People’s Data intern–to build a knowledge graph of military equipment owned by California law enforcement agencies (LEAs). First, we aggregated data from LEA-owned equipment inventories gathered by previous interns into a central tabular database. Identifying and matching identical equipment across LEAs, a process called deduplication, is crucial for making a dataset capable of facilitating comparative analysis. Since the equipment’s name isn’t as important to civilians as its capabilities, we researched each piece of equipment’s capabilities and used this information for deduplication.
With the tabular dataset constructed, we moved our work onto WikiData. Embedding knowledge in the graph was tricky as we needed to identify existing paradigms around similar military equipment that already existed in WikiData. Falling to align our terms with existing knowledge would lead to a siloed dataset that cannot take advantage of the knowledge that exists around it. Therefore, the conventions that emerged from previous WikiData contributors informed our translation protocol. We split the equipment in our dataset into categories and based each category’s data schema on existing entries for similar pieces of knowledge already embedded into WikiData.
In mid July, I brought our work to a convening on police militarization held by one of our partner organizations, the American Friends Service Committee. My goals were to understand where we stood in larger demilitarization efforts and present our research to attendees and understand how our work could aid their organizing efforts. Many attendees had been trying to understand the ways that equipment manufacturers and LEAs crafted rhetoric to improve their counter-rhetoric. My presentation garnered a surprising amount of interest for this reason and I am currently collaborating with community organizers to explore these questions.
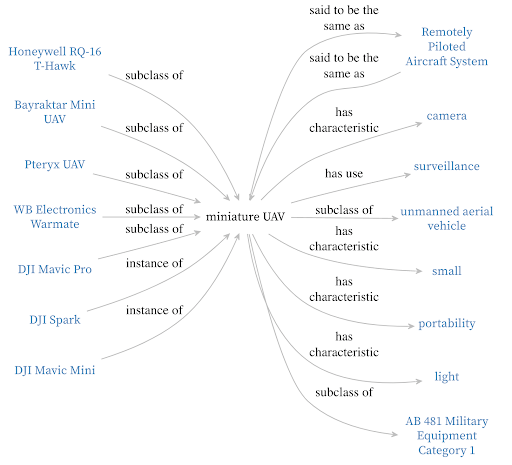
Finally, I made a knowledge graph-informed natural language query system. We incorporated natural language processing tools because traditional knowledge graph querying techniques such as SQL have rigid structures. This makes them struggle with questions that address uncertainty such as “Does an item like the Colt M4 Carbine that Santa Clara’s Police Department owns exist in the database? If not, what is the most similar item?” These queries also generally work with single pieces of information, making their outputs highly dependent on single sources.
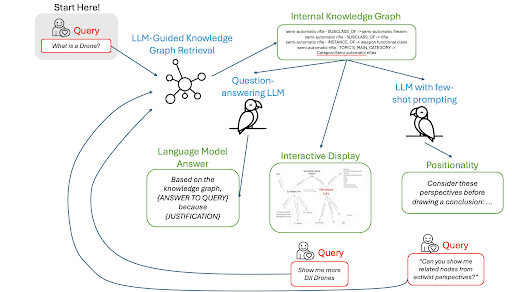
Our system uses a language model to synthesize graph information. Traversing this network to reach conclusions means aggregating information from interlinked sources. We hope that this hybrid graph structure, grounded in library practices and inspired by humanities theory, provides a wider set of perspectives for applications of AI to document collections.